 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpecDB: LLM-Generated Customized Databases via Feature-Oriented Decomposition
May 29, 2026Mainstream relational databases ship a uniform feature set across deployments, although individual workloads exercise only a fraction of the available subsystems. We investigate whether a database can instead be generated on demand with a feature set matched to the target workload. We present SpecDB, a system that uses large language models (LLMs) to synthesize customized relational databases. We survey 9 production systems and decompose them into 10 functional modules, each further divided into implementation variants. To capture cross-module dependencies, including cases where implementations in disjoint subtrees must be co-designed, we adopt the FODA feature model and extend it with a cooperate edge, yielding a dependency graph DBGraph. SpecDB operationalizes DBGraph through a layered module-construction pipeline in which each module is generated, validated, and integrated by a dedicated subagent (driven by three inner agents: Main, Tester, Architect), and a Refining Agent that iteratively repairs and tunes the assembled database against a user-supplied refining harness with read-only access to existing database source code. A companion selection component translates a natural-language workload description into a set of implementation variants, providing an end-to-end pipeline from workload description to deployable database. We evaluate SpecDB on TPC-C with BenchmarkSQL. The generated database (23,779 lines of Rust) completes 60-minute TPC-C at 1 and 10 warehouses with zero errors. At 10 warehouses it reaches tpmC=130, compared to 128 for PostgreSQL and 127 for MySQL, with comparable latency at ~3% of their code size. Because the agent operates at module-specification level rather than product source, it can in principle combine techniques across system boundaries. Paired with falling LLM costs, generating a purpose-built database for a target workload is becoming straightforward.
A Hypergraph-Based Framework for Exploratory Business Intelligence
Mar 11, 2026Business Intelligence (BI) analysis is evolving towards Exploratory BI, an iterative, multi-round exploration paradigm where analysts progressively refine their understanding. However, traditional BI systems impose critical limits for Exploratory BI: heavy reliance on expert knowledge, high computational costs, static schemas, and lack of reusability. We present ExBI, a novel system that introduces the hypergraph data model with operators, including Source, Join, and View, to enable dynamic schema evolution and materialized view reuse. Using sampling-based algorithms with provable estimation guarantees, ExBI addresses the computational bottlenecks, while maintaining analytical accuracy. Experiments on LDBC datasets demonstrate that ExBI achieves significant speedups over existing systems: on average 16.21x (up to 146.25x) compared to Neo4j and 46.67x (up to 230.53x) compared to MySQL, while maintaining high accuracy with an average error rate of only 0.27% for COUNT, enabling efficient and accurate large-scale exploratory BI workflows.
Graphy'our Data: Towards End-to-End Modeling, Exploring and Generating Report from Raw Data
Feb 24, 2025


Large Language Models (LLMs) have recently demonstrated remarkable performance in tasks such as Retrieval-Augmented Generation (RAG) and autonomous AI agent workflows. Yet, when faced with large sets of unstructured documents requiring progressive exploration, analysis, and synthesis, such as conducting literature survey, existing approaches often fall short. We address this challenge -- termed Progressive Document Investigation -- by introducing Graphy, an end-to-end platform that automates data modeling, exploration and high-quality report generation in a user-friendly manner. Graphy comprises an offline Scrapper that transforms raw documents into a structured graph of Fact and Dimension nodes, and an online Surveyor that enables iterative exploration and LLM-driven report generation. We showcase a pre-scrapped graph of over 50,000 papers -- complete with their references -- demonstrating how Graphy facilitates the literature-survey scenario. The demonstration video can be found at https://youtu.be/uM4nzkAdGlM.
HybridGNN: Learning Hybrid Representation in Multiplex Heterogeneous Networks
Aug 03, 2022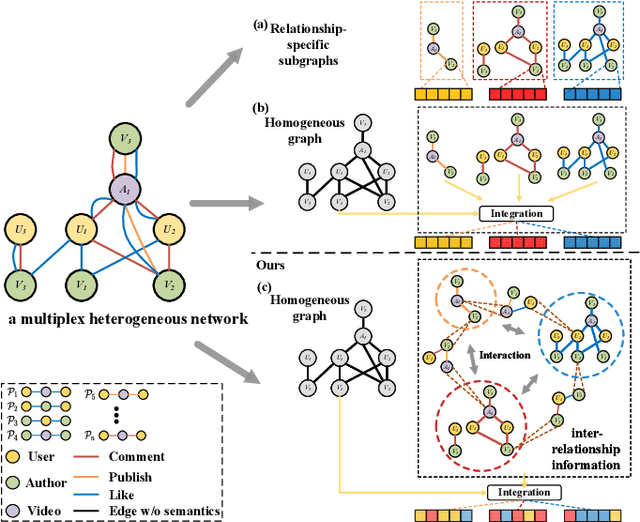
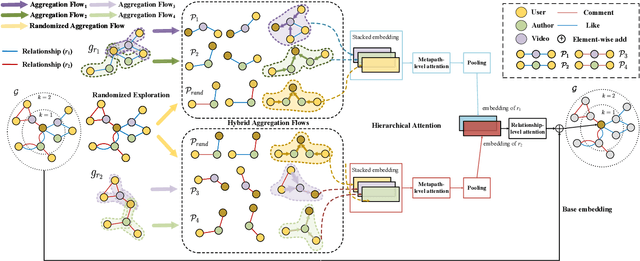
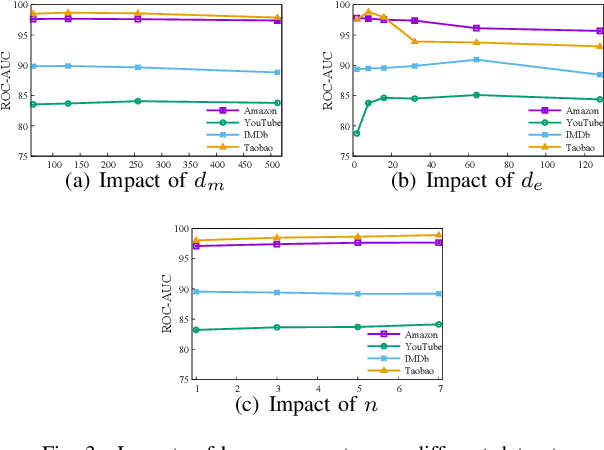
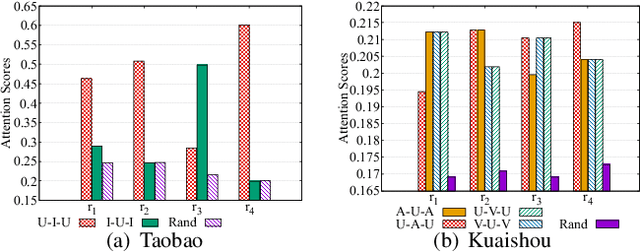
Recently, graph neural networks have shown the superiority of modeling the complex topological structures in heterogeneous network-based recommender systems. Due to the diverse interactions among nodes and abundant semantics emerging from diverse types of nodes and edges, there is a bursting research interest in learning expressive node representations in multiplex heterogeneous networks. One of the most important tasks in recommender systems is to predict the potential connection between two nodes under a specific edge type (i.e., relationship). Although existing studies utilize explicit metapaths to aggregate neighbors, practically they only consider intra-relationship metapaths and thus fail to leverage the potential uplift by inter-relationship information. Moreover, it is not always straightforward to exploit inter-relationship metapaths comprehensively under diverse relationships, especially with the increasing number of node and edge types. In addition, contributions of different relationships between two nodes are difficult to measure. To address the challenges, we propose HybridGNN, an end-to-end GNN model with hybrid aggregation flows and hierarchical attentions to fully utilize the heterogeneity in the multiplex scenarios. Specifically, HybridGNN applies a randomized inter-relationship exploration module to exploit the multiplexity property among different relationships. Then, our model leverages hybrid aggregation flows under intra-relationship metapaths and randomized exploration to learn the rich semantics. To explore the importance of different aggregation flow and take advantage of the multiplexity property, we bring forward a novel hierarchical attention module which leverages both metapath-level attention and relationship-level attention. Extensive experimental results suggest that HybridGNN achieves the best performance compared to several state-of-the-art baselines.